Approach & Findings
Problem Setting
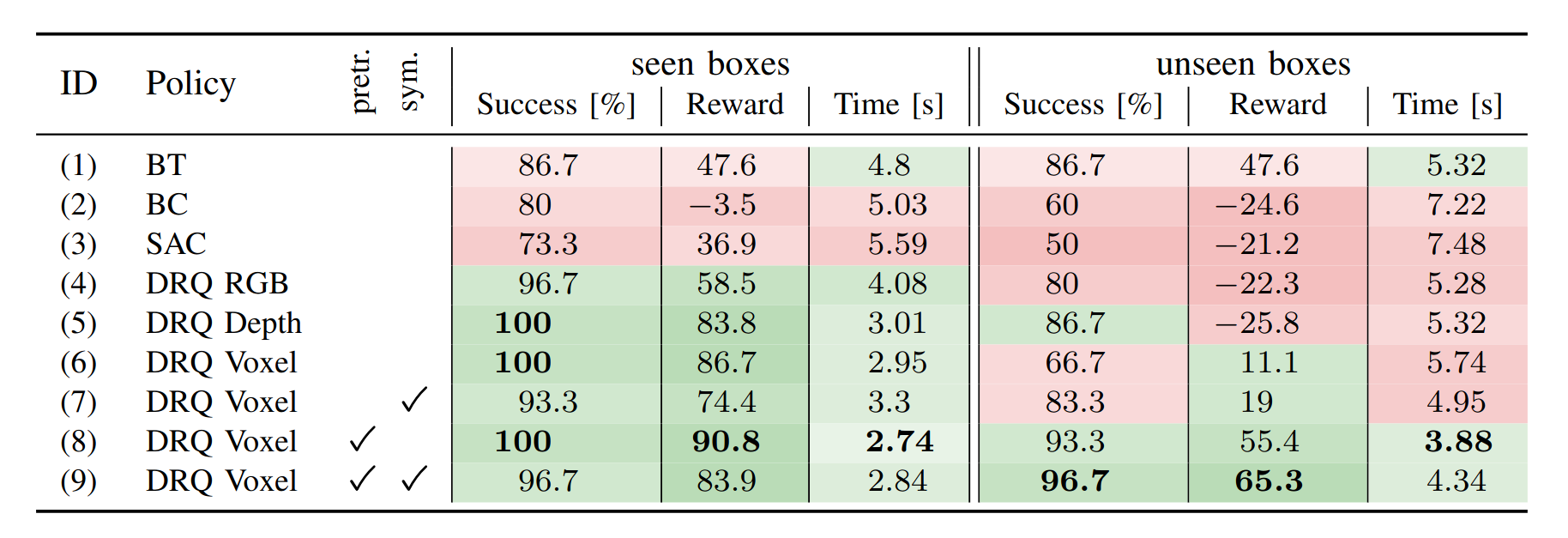
Reliable object manipulation with vacuum grippers is challenging due to variations in object size, shape, and surface texture. Traditional visual feedback struggles to generalize, making reinforcement learning with spatial representations a promising approach.
Setup


We employ a UR5 robotic arm with a Robotiq EPick vacuum gripper, equipped with two Intel RealSense depth cameras. The system captures spatial information using voxel grids, depth images, and RGB inputs, which are processed by different encoder architectures.
Training

We build on the Sample-Efficient Robotic Reinforcement Learning (SERL) framework, comparing different perception strategies: visual encoders (ResNet), depth maps, and voxel grids (3D convolutions). Training is conducted in a real-world environment with diverse box shapes and conditions. Actor and Learner nodes run simultaneously, using AgentLace.